Site Reliability Engineering یا SRE رویکردی است که توسط گوگل معرفی شد و ترکیبی از مهندسی نرمافزار و عملیات فناوری اطلاعات است. SRE با هدف تضمین قابلیت اطمینان، مقیاسپذیری، و عملکرد سیستمها، نقش مهمی در تکامل DevOps ایفا میکند. در این مقاله، اصول SRE، تفاوتها و شباهتهای آن با DevOps، و نحوه پیادهسازی آن بررسی میشود.
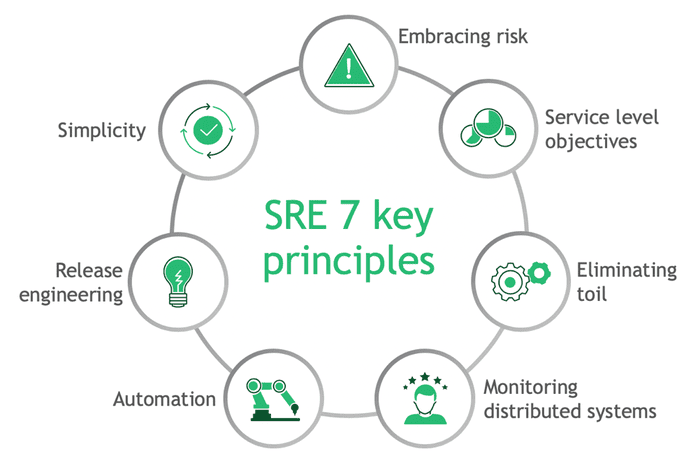
اصول SRE
SRE بر چند اصل کلیدی استوار است:
- Error Budget: تعادل بین قابلیت اطمینان و سرعت نوآوری.
- Service Level Indicators (SLIs): معیارهایی مانند زمان پاسخگویی.
- Service Level Objectives (SLOs): اهداف مشخص برای SLIs.
- Service Level Agreements (SLAs): توافقنامههای رسمی با مشتریان.
- Automation: کاهش وظایف دستی با ابزارهای خودکار.
نقش SRE در DevOps
SRE اصول DevOps مانند خودکارسازی و همکاری را تقویت میکند اما بر قابلیت اطمینان سیستم تمرکز دارد. SRE به تیمهای DevOps کمک میکند تا:
- کیفیت خدمات را با معیارهای دقیق پایش کنند.
- فرآیندهای واکنش به حوادث را بهبود بخشند.
- زمان قطعی را کاهش دهند.
ابزارهای SRE
ابزارهایی مانند Prometheus، Grafana، و PagerDuty برای مانیتورینگ و مدیریت حوادث در SRE استفاده میشوند.
مزایا و چالشها
| مزیت | چالش |
|---|---|
| افزایش قابلیت اطمینان | نیاز به تخصص فنی بالا |
| بهبود تجربه مشتری | پیچیدگی در تعریف SLO |
جمعبندی
SRE مکملی قدرتمند برای DevOps است که با تمرکز بر قابلیت اطمینان و خودکارسازی، به سازمانها کمک میکند تا سیستمهای پایدار و مقیاسپذیر ایجاد کنند. پیادهسازی SRE نیازمند فرهنگسازی و ابزارهای مناسب است، اما نتایج آن ارزش سرمایهگذاری را دارد.